★使用免寫程式的Web Scraper爬蟲工具和Python輕鬆學習網路爬蟲!
*本書使用Web Scraper瀏覽器擴充功能的爬蟲工具,讓你不用撰寫程式碼,就可以建立CSS選擇器的網站爬取地圖從網站擷取資料,不只能夠輕鬆爬取約7~8成網站,更透過Web Scraper工具讓你輕鬆一邊爬一邊學習HTML標籤+CSS選擇器,輕鬆了解Web網頁內容和各種網站巡覽結構。
*Python網路爬蟲程式不只能夠爬取Web Scraper工具爬取的網站內容,對於進階JavaScript動態和使用者互動網站,我們可以配合Python+Selenium爬取各種使用者互動網站,讓你在瀏覽器看得到的資料,就可以爬到資料;最後說明Python的Pandas資料清理和Plotly資料視覺化。
目錄
第一篇:Web Scraper網路爬蟲-免寫程式邊爬邊學HTML+CSS
第1章 認識網路爬蟲、HTML和CSS
第2章 爬取HTML標題、段落與文字格式標籤
第3章 爬取清單項目和表格標籤
第4章 爬取圖片和超連結標籤
第5章 爬取HTML容器和版面配置標籤
第6章 爬取階層選單和上/下頁巡覽網站
第7章 爬取頁碼、更多按鈕和無限捲動頁面巡覽的網站
第8章 Web Scraper爬蟲實戰:新聞、商務和金融數據爬取
第二篇:Python網路爬蟲-網路資料擷取「全方位」實戰
第9章 認識Python網路爬蟲
第10章 使用requests和Selenium取得網路資料
第11章 Beautiful Soup剖析與擷取網頁資料
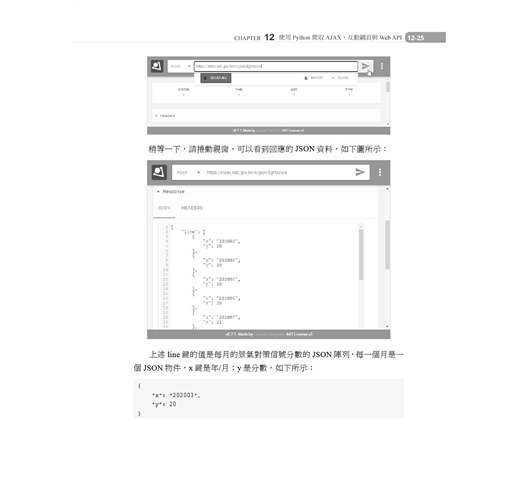
第12章 使用Python爬取AJAX、互動網頁與Web API
第13章 Python爬蟲實戰(一):爬取清單、表格與分頁資料
第14章 Python爬蟲實戰(二):Web API、AJAX與互動網頁資料爬取
第三篇:Python大數據分析-資料清理與資料視覺化
第15章 Pandas資料清理-pandas
第16章 Python資料視覺化-plotly
附錄 A Python程式設計入門(電子書,請線上下載)
附錄 B 離線安裝本書使用的瀏覽器擴充功能(電子書,請線上下載)
附錄 C Web Scraper 爬蟲網站地圖(電子書,請線上下載)
第一篇:Web Scraper網路爬蟲-免寫程式邊爬邊學HTML+CSS
第1章 認識網路爬蟲、HTML和CSS
第2章 爬取HTML標題、段落與文字格式標籤
第3章 爬取清單項目和表格標籤
第4章 爬取圖片和超連結標籤
第5章 爬取HTML容器和版面配置標籤
第6章 爬取階層選單和上/下頁巡覽網站
第7章 爬取頁碼、更多按鈕和無限捲動頁面巡覽的網站
第8章 Web Scraper爬蟲實戰:新聞、商務和金融數據爬取
第二篇:Python網路爬蟲-網路資料擷取「全方位」實戰
第9章 認識Python網路爬蟲
第10章 使用requests和Selenium取得網路資料
第11章 Beautiful Soup...
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。