掌握大數據資料處理與分析的必備套件:PANDAS
全方位了解Pandas程式庫的特性,進行高效能資料處理及分析Pandas是Python底下、用於實際資料分析上很受歡迎的一個套件。它提供有效率、快速、高效能的資料結構,使得資料探索及分析非常簡易。本書將引導讀者熟悉Pandas程式庫提供的各項完整功能,以進行資料的操控及分析。你將學到在Python底下如何用Pandas進行資料分析。我們從資料分析的概觀開始,接著反覆地進行資料建模、從遠端來源存取資料、利用索引進行數值及統計分析、執行聚合分析,最後把統計資料視覺化,並且應用到金融領域。
從本書獲取這些知識後,不但可快速認識Pandas,也具備了將其應用到資料操作、資料分析、資料科學等領域的能力。
【適用讀者】本書適合資料科學家、資料分析師、想用Pandas進行資料分析的Python程式設計師以及任何對資料分析感興趣的人閱讀。如果你具有一些統計及程式設計知識,則對於學習本書內容將會更有幫助,但是即使沒有統計及程式設計知識,或者沒有接觸過Pandas的經驗,也沒有關係。
【你能夠從本書學習到】◎了解資料分析師及資料科學家對於蒐集、解讀資料的看法。
◎了解Pandas如何支援全程的資料分析程序。
◎善用Pandas序列及資料框物件來表示單變數及多變數資料。
◎利用Pandas切割資料,以及從多個來源進行資料的結合、分組、聚合等操作。
◎學習如何從外部來源,如檔案、資料庫以及網站服務存取資料。
◎表示及操控時間序列資料,以及了解與此類資料相關的許多複雜之處。
◎學習如何將統計資料視覺化。
◎學習如何利用Pandas解決金融領域常見的幾個資料表示及分析方面的問題。
作者簡介:
Michael Heydt
Michael Heydt是技術專家、企業家、也是教育家,擁有幾十年的軟體發展、金融及商品交易經驗。他在華爾街專精發展分散式、基於參與者、高效能、高可用性的交易系統這方面有廣泛的經驗。他是Micro Trading Services公司的創辦人(一家為金融及商品交易來打造雲端及微型服務軟體解決方案的公司)。他擁有Drexel大學的數學及電腦科學碩士學位,以及賓州大學應用科學院及華頓商學院的在職科技管理碩士學位。
目錄
Chapter 1:pandas及資料分析
1.1 pandas介紹
1.2 資料操控、分析、科學以及pandas
1.3 資料分析程序
1.4 本書章節與程序的關聯性
1.5 pandas旅程中必須具備的資料及分析觀念
1.6 pandas用到的其他Python程式庫
1.7 小結
Chapter 2:啟動並運行pandas
2.1 安裝Anaconda
2.2 IPython及Jupyter筆記本
2.3 介紹pandas序列及資料框
2.4 視覺化
2.5 小結
Chapter 3:用序列表示單變數資料
3.1 設定pandas
3.2 建立序列
3.3 .index及.values屬性
3.4 序列的大小及形狀
3.5 在序列建立時指定索引
3.6 頭、尾、選取
3.7 以索引標籤或位置提取序列值
3.8 把序列切割成子集合
3.9 利用索引標籤實現對齊
3.10 執行布林選擇
3.11 將序列重新索引
3.12 原地修改序列
3.13 小結
Chapter 4:用資料框表示表格及多變數資料
4.1 設定pandas
4.2 建立資料框物件
4.3 存取資料框的資料
4.4 利用布林選擇選取列
4.5 跨越行與列進行選取
4.6 小結
Chapter 5:操控資料框結構
5.1 設定pandas
5.2 重新命名行
5.3 利用[]及.insert()增加新行
5.4 利用擴展增加新行
5.5 利用串連增加新行
5.6 改變行的順序
5.7 取代行的內容
5.8 刪除行
5.9 附加新列
5.10 列的串連
5.11 經由擴展增加及取代列
5.12 使用.drop()移除列
5.13 利用布林選擇移除列
5.14 使用切割移除列
5.15 小結
Chapter 6:索引資料
6.1 設定pandas
6.2 索引的重要性
6.3 pandas 的索引型別
6.4 使用索引
6.5 階層式索引
6.6 小結
Chapter 7:類別資料
7.1 設定pandas
7.2 建立類別物件
7.3 重新命名類別
7.4 附加新類別
7.5 移除類別
7.6 移除未使用的類別
7.7 設定類別
7.8 類別物件的敘述性資訊
7.9 學校成績轉換
7.10 小結
Chapter 8:數值與統計方法
8.1 設定pandas
8.2 對pandas物件執行算術運算
8.3 在pandas物件上執行統計程序
8.4 小結
Chapter 9:存取資料
9.1 設定pandas
9.2 處理CSV及文字/表格格式的資料
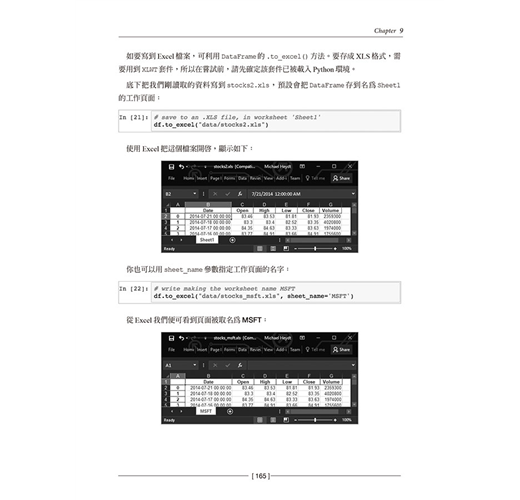
9.3 讀寫Excel格式資料
9.4 讀寫JSON檔案
9.5 從網站讀取HTML資料
9.6 讀寫HDF5格式檔案
9.7 存取網站上的CSV資料
9.8 讀寫SQL資料庫
9.9 從遠端資料服務讀取資料
9.10 小結
Chapter 10:整理資料
10.1 設定pandas
10.2 資料整理的意涵
10.3 如何處理資料遺漏
10.4 處理重複資料
10.5 資料轉換
10.6 小結
Chapter 11:結合、關聯以及重塑資料
11.1 設定pandas
11.2 串連幾個物件的資料
11.3 合併與連結資料
11.4 資料值與索引的樞紐操作
11.5 堆疊與解堆疊
11.6 堆疊資料帶來的效能好處
11.7 小結
Chapter 12:資料聚合
12.1 設定pandas
12.2 拆開、套用、結合(SAC)模式
12.3 範例資料
12.4 拆開資料
12.5 套用聚合函數、轉換以及過濾
12.6 轉換分組資料
12.7 過濾分組資料
12.8 小結
Chapter 13:時間序列建模
13.1 設定IPython筆記本
13.2 日期、時間、區間的表示方法
13.3 時間序列資料簡介
13.4 使用偏移值計算新日期
13.5 利用Period表示持續時間
13.6 處理日曆中的假日
13.7 利用時區正規化時間戳記
13.8 操控時間序列資料
13.9 時間序列的移動視窗運算
13.10 小結
Chapter 14:視覺化
14.1 設定pandas
14.2 Pandas的基本繪圖
14.3 建立時間序列圖表
14.4 統計分析常見的繪圖
14.5 在單一圖表中手動顯示多張繪圖
14.6 小結
Chapter 15:歷史股價分析
15.1 設定IPython筆記本
15.2 從Google取得與組織股票資料
15.3 繪製股價時間序列的圖
15.4 繪製成交量序列的圖
15.5 計算簡易的每日收盤價變化百分比
15.6 計算簡易的股票每日累積報酬率
15.7 將每日報酬率重新取樣為每月報酬率
15.8 分析報酬率分布
15.9 移動平均計算
15.10 比較股票之間的平均每日報酬率
15.11 依每日收盤價的變化百分比找出股票相關性
15.12 計算股票波動率
15.13 決定風險相對於期望報酬率的關係
15.14 小結
Chapter 1:pandas及資料分析
1.1 pandas介紹
1.2 資料操控、分析、科學以及pandas
1.3 資料分析程序
1.4 本書章節與程序的關聯性
1.5 pandas旅程中必須具備的資料及分析觀念
1.6 pandas用到的其他Python程式庫
1.7 小結
Chapter 2:啟動並運行pandas
2.1 安裝Anaconda
2.2 IPython及Jupyter筆記本
2.3 介紹pandas序列及資料框
2.4 視覺化
2.5 小結
Chapter 3:用序列表示單變數資料
3.1 設定pandas
3.2 建立序列
3.3 .index及.values屬性
3.4 序列的大小及形狀
3.5 在序列建立時指定索引
3.6 頭、尾、選取
3.7 ...
商品資料
出版社:博碩文化股份有限公司出版日期:2019-08-22ISBN/ISSN:9789864343898 語言:繁體中文For input string: ""
裝訂方式:平裝頁數:384頁
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。










































 收藏
收藏






