★用「關鍵字」掌握重點!
從AI工程師到相關行業的營業員
以及商務人士都能高效理解!監督式學習
非監督式學習
強化學習
CNN
RNN
BERT
NLP
語料庫
Transformer
GPT-3
VAE
GAN
通用性能
圖像分割
線性迴歸模型
決策樹
隨機森林
XGBoost
邏輯迴歸模型
k-NN
k-means演算法
★最完整的AI通識入門寶典!
除了上述的AI關鍵字之外,還搭配大量圖表、範例深入淺出解說。
只要讀完這本書,就能全方位掌握AI的原理與應用方式!!
★和日本多位人工智慧專家
一起學習、認識AI!
從AlphaGo、Deepfake到ChatGPT,
AI與其相關技術已是現代人日漸仰賴的存在。
透過本書,我們便可高效習得和AI有關的知識,
並對未來的趨勢有更清晰的洞見。
商品特色由多位日本AI專家共同執筆
一本就能掌握最完整的AI原理與應用
列表資料、圖像辨識、機器學習演算法X完整圖解介紹
豐富的圖表解析X專題實作
作者簡介:
高橋海渡(Takahashi Kaito)
第1、2章的主筆。曾在AI供應商從事新事業開發和研究機構的AI體驗講師。現為開發者,從事機器學習模型的製作和Web開發工作。
立川裕之(Tachikawa Hiroyuki)
第6章的主筆。獨立資料分析顧問。
曾任事業公司的法人銷售員和SaaS的商務主任,後參與籌劃了株式會社DataMix。以資料分析顧問和研修講師等身份參與過各種項目後獨立。現從事資料分析顧問、演算法開發、資料整備支援等工作。
小西功記(Konishi Kohki)
第4、5章的主筆。任職於株式會社Nikon先進技術開發本部數理技術研究所。
生於和歌山縣。曾在美國勞倫斯柏克萊國家實驗室等機構研究觀測宇宙學,並擔任過資料科學家。於東京大學理學系研究科專攻物理學,取得博士學位。後進入株式會社Nikon,自2015年起任AI(機器學習)工程師。主要研究最尖端的圖像分析技術發展,以及AI技術的社會應用。在國內外學會發表過多項專利。
小林寬子(Kobayashi Hiroko)
第3章主筆。任職於株式會社Nikon先進技術開發本部數理技術研究所。
生於東京都。進入株式會社Nikon時任職於經理部門,後為參與開發業務主動申請調職,現從事應用自然語言處理的市場分析和圖像辨識等技術的研究開發工作。JDLA G檢定2020年第二名,2020年度日本經濟產業省AI Quest修畢。
石井大輔(Ishii Daisuke)
第4章主筆。本書的企劃統籌者。株式會社Kiara代表取締役。
生於岡山縣。在京都大學主修數學,後進入伊藤忠商事,在歐洲開發新事業。2016年成立專攻AI和機器學習的研究社群「TeamAI」。通過1000次的讀書會聚集了1萬名會員。2019年針對外國市場推出可即時翻譯100國語言的Chatbot App「Kiara」。500 Startups Singapore(受日本經濟產業省JETRO補助)畢業生。著有《寫給想成為機器學習工程師的人——以AI為天職》(翔泳社)等書。
■執筆協助
澤井 悠(第3章)/齋藤 豪(第3章)/信田 萌伽(第4、5章)
章節試閱
什麼是機器學習
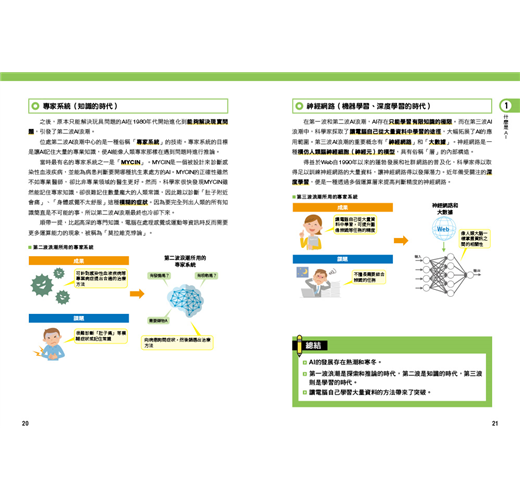
所謂機器學習,是一種透過讓電腦學習大量資料來提高判斷精度的技術。機器學習的代表性方法有「監督式學習」、「非監督式學習」、「強化學習」。
機器學習的概念和主要方法
機器學習是一種讓電腦模仿人類透過經驗學習事物的方法,來提高電腦判斷精度的資料分析技術。其基本過程是將大量資料輸入電腦,讓電腦反覆學習,然後從資料中找出特定的模式。機器學習主要有「監督式學習」、「非監督式學習」、「強化學習」三種方法。
監督式學習是把「輸入資料」和「正解標註」成對輸入電腦,讓電腦學習資料的特徵。非監督式學習則是不給予正解標註,只大量輸入資料,讓電腦從資料中學習特徵。強化學習則是基於特定目標,對正確的行動給予獎勵,錯誤的行動給予懲罰,讓電腦學會能達成目標的最佳行動。
監督式學習的代表性演算法
監督式學習所用的演算法主要有「分類(Classification)」和「迴歸(Regression)」。
分類就是預測輸入的資料屬於哪一類。比如判斷電子郵件是正常郵件還是垃圾郵件的垃圾郵件過濾,以及識別圖中物體的圖像辨識等,都應用了分類演算法。
迴歸則是預測輸入資料的連續值。比如預測電力消耗量的變化或網站的點擊數等使用手中已有的資料來預測未來數值的任務,都是應用了迴歸演算法。
監督式學習只要解決了如何獲得附有正解標註的資料這道難關,就可以輕鬆完成,可說是最流行的機器學習方法。監督式學習的主要演算法如下表所示。另外在機器學習中,已訓練完畢、可以辨識特定種類或模式的檔案或運算方法稱為「模型」。
非監督式學習的代表性演算法
非監督式學習使用的演算法主要有「分群」和「降維」。分群主要是用來找出資料的傾向。包含將特徵相近的資料分割成k個組別的k-means法、將相似的資料按順序分組的階層式分群等等。
降維則是在盡可能保持資訊的情況下,將高維資料轉換成低維資料。比如,假使今天收集到一個10維的資料,人類是沒有辦法直接檢驗的。所以要把這個資料轉換成2維資料後再找出資料的特徵。以我們身邊的例子來說,比如測量身高和體重傾向的BMI就是一種降維算法。
當需要替監督式學習的訓練資料加上正解標註,或是想替客戶的購物偏好分類時,經常會使用非監督式學習方法。
強化學習的代表性演算法
強化學習是一種根據實際經驗嘗試犯錯,以找出「在特定情境中該怎麼做才好」的最佳行動方針來達成特定目標的方法。
在強化學習中,電腦會以某個終點為目標,比如在圍棋或象棋中就是「贏得對局」,然後做出行動,再根據該行動的結果好壞決定下一個行動。因此跟監督式學習和非監督式學習比起來,強化學習是一種訓練難度較高的方法。另外,因為強化學習被應用在遊戲和自動駕駛中,跟其他方法相比,算是一種偏研究性質的機器學習方法。
強化學習也被應用在「推薦」、「異常偵測」、「頻繁樣式的匹配」等領域。
推薦算法被用於向使用者推薦可能符合其喜好的物件。比如購物網站常見的「其他人也買了這些商品」欄位、影音網站的「相關影片」等等,被用來讓使用者在網頁服務上停留更長時間或促銷商品。
異常偵測算法則被用來偵測信用卡的不正當使用行為或提早發現股價的異常變化等,用於偵測異常的資料模式。
頻繁樣式的匹配算法則是用來從資料中找出出現頻率高的模式。有名的例子有「啤酒和紙尿布經常被同時購買」。這就是由機器學習從消費資訊中挖掘到的模式。
什麼是機器學習
所謂機器學習,是一種透過讓電腦學習大量資料來提高判斷精度的技術。機器學習的代表性方法有「監督式學習」、「非監督式學習」、「強化學習」。
機器學習的概念和主要方法
機器學習是一種讓電腦模仿人類透過經驗學習事物的方法,來提高電腦判斷精度的資料分析技術。其基本過程是將大量資料輸入電腦,讓電腦反覆學習,然後從資料中找出特定的模式。機器學習主要有「監督式學習」、「非監督式學習」、「強化學習」三種方法。
監督式學習是把「輸入資料」和「正解標註」成對輸入電腦,讓電腦學習資料的特徵。非監督式學習...
作者序
2022年是個難過的一年,才剛有國家宣布新冠疫情結束,歐洲就緊接著爆發戰爭。在這動盪的世界,以數學為首的邏輯思維的重要性與日俱增。而邏輯的論據則是數據。不只是大數據,新聞報紙上的內容也必須留意真偽,檢查有無謬誤,仔細思量後再下判斷,否則便有可能做出違逆趨勢變化的決定。尤其是科學思維,不論對蔬果店還是瑜伽老師都很重要。
AI浪潮已打著數位轉型之名生根落地。但另一方面,根據我在第一線的觀察,目前仍有99%的工作沒有引進AI。而範圍擴大到全球,恐怕仍有99.99%的市場還未開拓。我認為就連馬達加斯加的漁夫,也應該引進資料科學。
在大多數的職場,人們仍習慣把資料印出來丟著、進行無用的問卷調查、只使用沒有按ID分類的統計資料。雖然擁有足以稱為大數據的資料量,POS收銀機和總公司的會計仍完全分開,並在系統公司的政治鬥爭下難以無縫整合。
儘管日本數位廳正努力改善現狀,但要做的工作仍堆積如山。在戰爭影響下,網路安全AI和防範犯罪與恐攻的AI等新興領域也隨之出現。AI的工作永無止境。
本書是一本專為有意學習AI者而寫的通識性入門書。在第1、2章,我們將介紹AI的概要,解答「AI是什麼?」這個根本性問題,屬於基礎知識篇。
在第3章,我們會介紹自然語言處理,網羅從基礎的向量空間上的語言圖譜,到最新的Transformer等大型架構。在第4章則會介紹「GAN=生成對抗網路」。GAN源於圖像生成領域,近年也被用於生成音樂和文章(GPT),在最尖端的領域也屬於當紅技術。本章還將介紹包含實驗性質的社會應用在內的各種案例。
第5章將介紹近年發展最快速的圖像辨識領域。這領域的發展引爆點是第三波AI浪潮,在一開始就有很高辨識精度,以自動駕駛為首,許多充滿夢想的社會應用點子都已起步,存在各種不同的架構,發展出五花八門的產品。在第6章,我們將介紹資料科學中非常重要,而且在實務上經常出現的列表資料。諮詢業務和一般企業擁有的資料中最多的就是這種資料。本章將介紹最通用且可應用在眾多場景的知識技巧。
即使完全跨越新冠病毒和歐洲戰事,人類也還有氣候變遷、貧富差距、不治之症、幫助弱勢群體等許多未解的難題要面對。當然,其中有些問題更適合從社會學或哲學脈絡來解決。但是,如果輔以邏輯學和資料科學的話,無疑將有更好的證據支持,更容易成功。
大家因為興趣而做的拉麵店圖像分析和Netflix的節目評價分析等,也跟上述的項目同樣有意義。沒有什麼比找出自己的主題,並努力分析它們更有樂趣了。如果本書能成為你投入研究的契機,那就再好不過了。
得益於技術評論社的宮崎主哉先生,以及共筆的高橋海渡先生、立川裕之先生、小西功記先生、小林寬子小姐幾位出色成員幫助,本書才得以問世。誠心感謝他們。另外,我想在此一併向內人留衣和執筆期間誕生的小女晴表達感謝。
2022年11月 祈願烏克蘭與世界和平的杉並區民
合著者代表 石井大輔
2022年是個難過的一年,才剛有國家宣布新冠疫情結束,歐洲就緊接著爆發戰爭。在這動盪的世界,以數學為首的邏輯思維的重要性與日俱增。而邏輯的論據則是數據。不只是大數據,新聞報紙上的內容也必須留意真偽,檢查有無謬誤,仔細思量後再下判斷,否則便有可能做出違逆趨勢變化的決定。尤其是科學思維,不論對蔬果店還是瑜伽老師都很重要。
AI浪潮已打著數位轉型之名生根落地。但另一方面,根據我在第一線的觀察,目前仍有99%的工作沒有引進AI。而範圍擴大到全球,恐怕仍有99.99%的市場還未開拓。我認為就連馬達加斯加的漁夫,也應該引進資...
目錄
第1章
什麼是AI
01 AI的定義──12
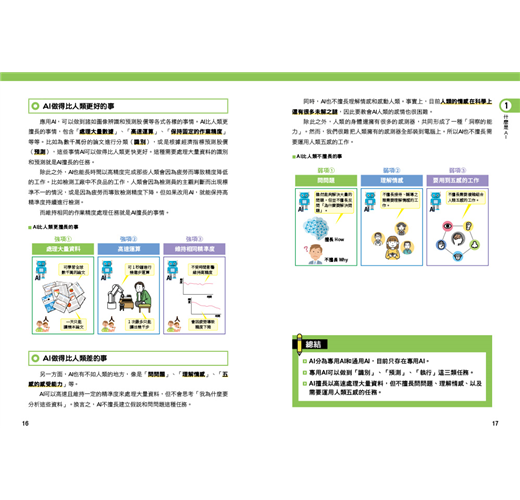
02 AI擅長與不擅長的領域──14
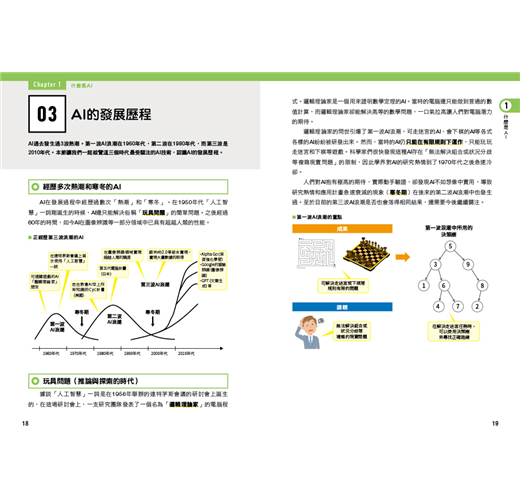
03 AI的發展歷程──18
04 什麼是機器學習──22
05 什麼是深度學習──26
06 機器學習與深度學習的差異──30
第2章
AI的基礎知識
07 機器學習與統計學──36
08 相關性與因果關係──40
09 機器學習與資料探勘──44
10 什麼是監督式學習──48
11 什麼是非監督式學習──52
12 什麼是強化學習──56
13 AI與大數據──60
14 從資料種類看AI的特徵──64
15 AI系統的開發流──68
第3章
自然語言處理的方法和模型
16 什麼是自然語言處理(NLP)──74
17 NLP的模糊性與困難──80
18 NLP的預處理──84
19 語言模型與分散式表徵──90
20 標注語料庫與雙語語料庫──98
21 遞歸神經網路(RNN)──104
22 Transformer──110
23 BERT──116
24 GPT-3──122
第4章
以GAN為基礎的生成模型
25 進軍創作領域的AI──130
26 以生成模型為基礎的演算法──132
27 用GAN生成圖像──138
28 敵對攻擊與防禦──144
29 GAN的未來發展──148
第5章
圖像辨識的方法和模型
30 圖像辨識的任務──156
31 卷積神經網路(CNN)──160
32 引爆圖像辨識發展的CNN──164
33 CNN的精度與大小平衡──168
34 訓練的技巧1──172
35 訓練的技巧2──176
36 深度學習的可解釋性──180
37 圖像辨識的評價指標──184
38 精度的評價指標與通用性能──188
第6章
列表資料的機器學習演算法
39 列表資料的預處理──194
40 監督式學習1:線性迴歸模型──196
41 監督式學習2:決策樹──200
42 監督式學習3:隨機森林──204
43 監督式學習4:XGBoost──208
44 監督式學習5:邏輯迴歸模型──212
45 監督式學習6:神經網路──216
46 監督式學習7:k-NN(k-Nearest Neighbor)──220
47 非監督式學習1[分群]:k-means法──222
48 非監督式學習2[分群]:階層式分群──226
49 非監督式學習3[分群]:譜分群──228
50 非監督式學習4[降維]:PCA(主成分分析)──232
51 非監督式學習5[降維]:UMAP──236
52 非監督式學習6[降維]:矩陣分解──240
53 非監督式學習7[降維]:自編碼機──244
結語──248
索引──249
作者介紹──254
第1章
什麼是AI
01 AI的定義──12
02 AI擅長與不擅長的領域──14
03 AI的發展歷程──18
04 什麼是機器學習──22
05 什麼是深度學習──26
06 機器學習與深度學習的差異──30
第2章
AI的基礎知識
07 機器學習與統計學──36
08 相關性與因果關係──40
09 機器學習與資料探勘──44
10 什麼是監督式學習──48
11 什麼是非監督式學習──52
12 什麼是強化學習──56
13 AI與大數據──60
14 從資料種類看AI的特徵──64
15 AI系統的開發流──68
第3章
自然語言處理的方法和模型
16 什麼是自然語言處理(NLP...
商品資料
出版社:台灣東販股份有限公司出版日期:2023-12-27ISBN/ISSN:9786263791848 語言:繁體中文For input string: ""
裝訂方式:平裝頁數:256頁
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。


 收藏
收藏

 7二手徵求有驚喜
7二手徵求有驚喜