由淺入深了解Scrapy爬蟲框架,讓你從零開始建立高效率爬蟲!
◆自學網路爬蟲沒問題,手把手教學讓你無痛上手
◆完整的網路爬蟲和Scrapy知識,資料取得更輕鬆
◆學會各種套件和實作範例,讓你的爬蟲比別人更有效率
本書內容改編自第11屆iT邦幫忙鐵人賽的AI & Data組優選網路系列文章─《爬蟲在手、資料我有 - 30 天 Scrapy 爬蟲實戰》。在AI的大時代中,「資料來源」是基礎中的基礎,但網路上的資料豐富又繁雜,總不可能都靠人工來蒐集資料。這時就是爬蟲出場的時候了!本書會帶讀者了解爬蟲的基礎知識,克服爬蟲常見的問題,最後可以寫出維護成本低、執行效率高的爬蟲程式。
│四大重點│
★初學者必備的爬蟲指南,大大降低你的學習門檻
網路爬蟲妙計已為你爬取完成!從安裝環境、認識架構、資料儲存、除錯到各類型網站實作,本書將一步步帶你學會網路爬蟲。
★全面解析各種知識,爬蟲能力再提升
不只教你如何進行網路爬蟲,還要帶你深入Scrapy架構,並特別介紹NoSQL、反反爬蟲。提升你的爬蟲技能,擁有越級打怪的神力。
★活用各種套件,打造高效率爬蟲
本書將手把手帶你活用各種套件,並從範例中學會撰寫精簡有效的程式碼,讓你克服問題、達成任務,邁向高效率的資料取得之路。
★爬取資料生活化,就像抓寶一樣好玩有趣!
你會學到如何抓取PTT、Mobile01、新聞網站、股市網站資料,你想要的各種資料都能輕鬆取得。
│適用讀者│
◆對Python有基礎了解,想要學習爬蟲程式的初學者
◆為爬蟲維護和效能所苦,想要更進一步的開發人員
【下載範例程式檔案】
本書範例檔下載網址:
https://github.com/rex-chien/ithome-scrapy
作者簡介:
簡學群
在業界打滾五年的C#後端工程師。興趣使然,也斜槓於Python爬蟲、PHP Laravel、Vue.js、Java Spring等領域,熱愛跟朋友研究和分享新技術。
連續參加第10、11屆iT邦幫忙鐵人賽且完賽,更在第11屆iT邦幫忙鐵人賽中,以《爬蟲在手、資料我有 -30 天 Scrapy 爬蟲實戰》系列文章,獲得AI & Data組優選。
目錄
前言
目錄
第1章 基礎知識
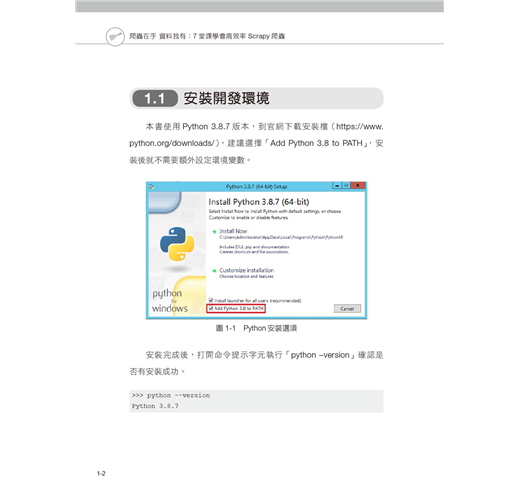
1.1 安裝開發環境
1.2 網路資料常見的格式
第2章 爬蟲基礎
2.1 剖析來源資料
2.2 從網路上取得資料
第3章 基礎實戰–蒐集iThelp 文章資料
3.1 列表頁
3.2 換頁
3.3 內文
3.4 文章資訊
3.5 回文
第4章 資料持久化
4.1 PostgreSQL
4.2 NoSQL
第5章 進階爬蟲
5.1 反反爬蟲
5.2 練習其他網站
第6章 Scrapy 基礎
6.1 Scrapy 架構
6.2 開發環境
6.3 實作Scrapy爬蟲
6.4 Scrapy的結構化資料-Item
6.5 在Scrapy中處理爬取結果-Item Pipelines
6.6 在Scrapy中處理請求和回應-Downloader Middlewares
6.7 Scrapy的設定
6.8 在Scrapy中操作瀏覽器
6.9 Scrapy的日誌
6.10 蒐集Scrapy的統計資訊
6.11 發送電子郵件
第7章 實戰Scrapy
7.1 Item Pipelines應用-儲存資料到 MongoDB
7.2 在程式中啟動Scrapy爬蟲
7.3 iThelp 的Scrapy 爬蟲
7.4 中央社新聞的Scrapy 爬蟲
7.5 PTT 的Scrapy 爬蟲
7.6 相同剖析邏輯的多個資料來源
前言
目錄
第1章 基礎知識
1.1 安裝開發環境
1.2 網路資料常見的格式
第2章 爬蟲基礎
2.1 剖析來源資料
2.2 從網路上取得資料
第3章 基礎實戰–蒐集iThelp 文章資料
3.1 列表頁
3.2 換頁
3.3 內文
3.4 文章資訊
3.5 回文
第4章 資料持久化
4.1 PostgreSQL
4.2 NoSQL
第5章 進階爬蟲
5.1 反反爬蟲
5.2 練習其他網站
第6章 Scrapy 基礎
6.1 Scrapy 架構
6.2 開發環境
6.3 實作Scrapy爬蟲
6.4 Scrapy的結構化資料-Item
6.5 在Scrapy中處理爬取結果-Item Pipelines
6.6 在Scrapy中處理請求和回應-Downloader Middlewares
6.7 S...
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。























 收藏
收藏