本書是臺大最受歡迎的統計通識課「統計與生活」指定教科書,
更為華人世界第一本特別為統計通識課編寫的課程用書,
適合人文、社科、法律、生物、醫學、公衛各領域相關課程使用。
本書為華人世界第一本統計通識課程之教科書,由國立臺灣大學農藝系與流病所劉仁沛教授、政治系洪永泰教授、公衛系與流病所蕭朱杏教授及數學系與流病所陳宏教授依據教學內容共同編寫而成。
有別於一般翻譯自國外教科書書中所使用的例子、數據與習題均為國外的經驗,本書改以臺灣及華人地區的實際問題、數據與例證為基礎,貼近學生的生活世界,讓學生可以輕鬆有效率地學習統計。
本書所談及之統計理論涵蓋一般統計科普書籍的範圍,所舉之例子遍及人文、法律、社科、生物、醫學、公衛、行政與其他科學領域等與生活息息相關之實例與議題。因此,本書適用於各學院統計相關課程及一般通識課程,並可作為一般讀者增進統計常識之科普書籍。
作者簡介:
劉仁沛 教授 (臺灣大學農藝系與流病所)
美國肯塔基大學統計學博士
研究專長:
臨床試驗設計分析、銜接性試驗設計分析、對等性設計與分析、生技產品製程與品管、動物毒性與毒理試驗、診斷工具之統計評估
洪永泰 教授 (臺灣大學政治系)
美國密西根大學生物統計學博士
研究專長:
抽樣調查、選舉預測、社會科學統計方法
蕭朱杏 教授 (臺灣大學公衛系與流病所)
美國卡內基馬隆大學統計學博士
研究專長:貝氏統計分析及計算、遺傳統計
陳 宏 教授 (臺灣大學數學系與流病所)
美國加州柏克萊大學統計學博士
研究專長:
半母數迴歸分析、闕失值數據分析、統計
章節試閱
第一章 資料從哪裡來
1.1 導讀
學習統計學的第一步,就是要認識「資料」(data),了解資料的基本型態及如何蒐集資料。而當我們在蒐集資料過程中,必須符合道德規範,以及使用正確地衡量工具,才能進行下一個步驟抽樣資料(第2 章)。本章節將介紹資料的不同型態、觀察性資料、實驗性資料、數據的展示、蒐集資料的道德規範及資料衡量工具的信度與效度。
1.2 資料的型態
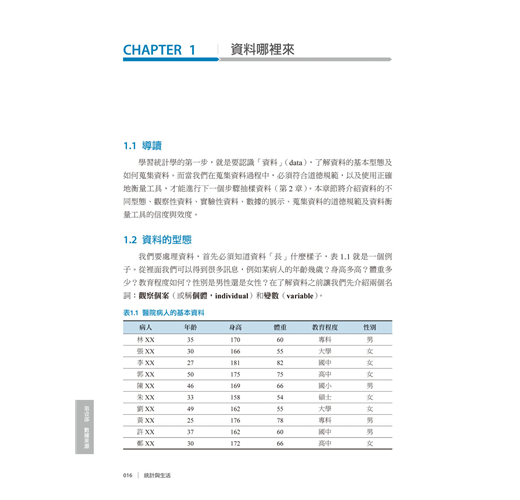
我們要處理資料,首先必須知道資料「長」什麼樣子,表1.1就是一個例子。從裡面我們可以得到很多訊息,例如某病人的年齡幾歲?身高多高?體重多少?教育程度如何?性別是男性還是女性?在了解資料之前讓我們先介紹兩個名詞:觀察個案(或稱個體,individual)和變數(variable)。
所謂個體,是指資料描述的主要對象。以表1.1 為例,個體是指醫院的病人,換句話說,這筆資料主要描述的對象就是醫院的病人。
所謂變數,又稱變項,用來描述個體的某種特性,依照特性的分類標準,可以為不同數值(亦稱變量)或類別出現次數,參考表1.1。例如林XX的年齡是35歲,張XX的年齡是30歲,李XX的年齡是27歲,年齡是用來描述病人的某種特性,因此年齡就是一個變數,每位病人的年齡可能有不一樣的值。同理,性別也是一個變數,例如林XX的性別是男性,張XX的性別是女性,李XX的性別是女性,其他如身高、體重和教育程度也都是變數。
變數根據類型的不同可分為兩種,第一種是類別變數(categorical variable),也稱為質性變數(qualitative variable)。參考表1.1,性別和教育程度都屬於類別變數,例如性別分成男性和女性,教育程度分成國小、國中、高中、專科、大學和碩士,因此類別變數是把個體分類,分成幾個不同的特性。
第二種是量化變數(quantitative variable),也稱為數量變數。參考表1.1, 年齡、身高和體重都屬於數量變數,數量變數的值是有意義的數字,例如林XX的年齡是35歲、張XX的身高是166公分和李XX的體重是82公斤都是在描述變數代表的意義。
資料來源
蒐集資料的方法主要有觀察法和實驗法。參考表1.2,利用觀察法所得到的資料稱為觀察性資料,利用實驗法所得到的資料稱為實驗性資料。
所謂觀察性資料(observational data),是指順其自然,這個世界是什麼, 它就是什麼,換句話說,訪問時看到什麼聽到什麼,就把它記錄下來,例如民意調查,或是田野調查所得到的資料。
所謂實驗性資料(experimental data),是指操之在我,可以掌控或操縱自然世界的。例如新藥測試,在實驗室裡面,研究人員可以用各種人工的方法操縱一些因素(factor)而取得測試資料。
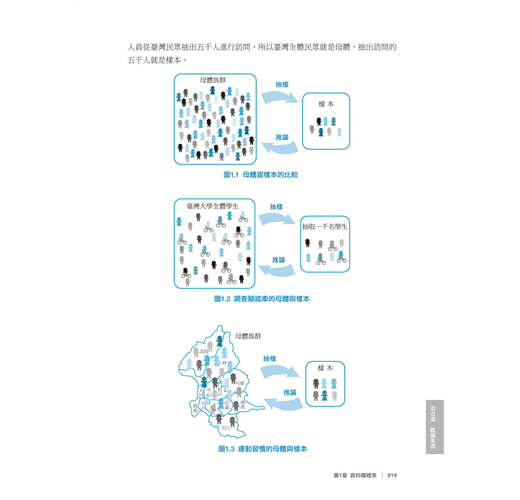
利用觀察法得到的資料是很常見的,而觀察性資料通常會有母體資料和樣本資料的區分。參考圖1.1,讓我們先大致了解一下母體(population)和樣本(sample)的差別。
所謂的母體,是指研究的全體對象;而所謂的樣本,則是從母體裡面抽取一部分,以便對母體做一些推論。我們用以下幾個例子來說明母體跟樣本的差別。
第一個例子是關於臺大學生騎腳踏車的調查,參考圖1.2,腳踏車對臺大學生而言是一個很方便的交通工具,如果想知道臺大學生騎腳踏車的比例,從臺大全體學生之中抽取一千人進行訪問,此時的母體就是臺灣大學全體學生,所抽取的一千人就是樣本。
第二個例子是臺北市民的運動習慣,參考圖1.3。運動可以舒緩壓力,增加抵抗力,促進身心健康,如果想知道臺北市民的運動習慣,從臺北市民之中抽出兩千人進行電話訪問,這裡臺北市全體人民就是母體,而樣本就是電話訪問的兩千人。
第三個例子是臺灣民眾的上網時間,參考圖1.4。近幾年來網路發達,許多民眾都從網路上取得資訊,如果想知道臺灣民眾每週花多少時間在網路上,研究人員從臺灣民眾抽出五千人進行訪問,所以臺灣全體民眾就是母體,抽出訪問的五千人就是樣本。
1.3 觀察性資料――順其自然
利用觀察法得到的資料稱為觀察性資料,參考圖1.5。通常我們看到觀察性資料時就會聯想到這個資料是從哪裡來的?它們有可能是來自於母體資料(如前例臺灣大學全體學生、臺北市全體人民、臺灣全體民眾等等),也有可能是樣本資料(如前例抽取一千名學生、電訪兩千名市民、訪問五千位民眾等等)。大家在一般媒體上面看到的資料,通常都會說明這個是抽樣資料或是母體資料。
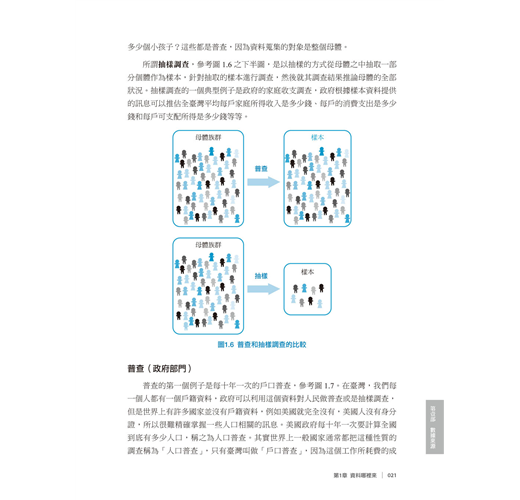
調查(survey)是蒐集資料很常見的方法之一,所取得的資料也是屬於觀察性資料的一種,而我們根據調查的範圍可將「調查」區分為普查(census) 跟抽樣調查(sample survey)兩種, 參考圖1.6所示,我們來比較普查跟抽樣調查的差異。
所謂普查,參考圖1.6之上半圖,是將整個母體納入觀察,以全部母體作為調查對象,換句話說,就是百分之百的抽樣。利用普查所得到的資料則是母體資料,例如臺灣有多少人?去年有多少人參加大學指考?去年有多少人結婚,多少人離婚,生下多少個小孩子?這些都是普查,因為資料蒐集的對象是整個母體。
所謂抽樣調查,參考圖1.6之下半圖,是以抽樣的方式從母體之中抽取一部分個體作為樣本,針對抽取的樣本進行調查,然後就其調查結果推論母體的全部狀況。抽樣調查的一個典型例子是政府的家庭收支調查,政府根據樣本資料提供的訊息可以推估全臺灣平均每戶家庭所得收入是多少錢、每戶的消費支出是多少錢和每戶可支配所得是多少錢等等。
普查(政府部門)
普查的第一個例子是每十年一次的戶口普查,參考圖1.7。在臺灣,我們每一個人都有一個戶籍資料,政府可以利用這個資料對人民做普查或是抽樣調查, 但是世界上有許多國家並沒有戶籍資料,例如美國就完全沒有,美國人沒有身分證,所以很難精確掌握一些人口相關的訊息。美國政府每十年一次要計算全國到底有多少人口,稱之為人口普查。其實世界上一般國家通常都把這種性質的調查稱為「人口普查」,只有臺灣叫做「戶口普查」,因為這個工作所耗費的成本相差非常多,人口普查難度較高,要花很多資源,但是戶口普查相對來說比較容易,利用戶籍資料,等於是在做戶口校正一樣,所以工作量少很多。
普查的第二個例子是臺灣每五年一次的工商及服務業普查,參考圖1.8。這個普查將全臺灣所有的公司機關行號都納入調查,包括營運狀況、資源分布、資本運用、生產結構及其他相關產業經濟活動狀況等都在調查範圍之內。
普查的第三個例子是臺灣每五年一次的農林漁牧業普查,參考圖1.9。這是調查全臺灣所有經營農林漁牧業生產和休閒活動的業者,針對他們的經營資源分布、生產結構、勞動力特性、資本設備及經營狀況等情形進行調查。
對一個講究行政效率的國家來講,平常一定要蒐集和分析這些統計數字。政府和民間都需要知道全國的工商及服務業與農林漁牧業所有的狀況,以作為擬訂各種相關政策的依據。
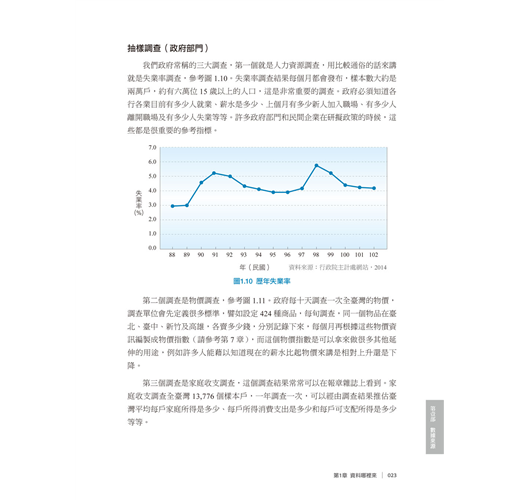
抽樣調查(政府部門)
我們政府常稱的三大調查,第一個就是人力資源調查,用比較通俗的話來講就是失業率調查,參考圖1.10。失業率調查結果每個月都會發布,樣本數大約是兩萬戶,約有六萬位15歲以上的人口,這是非常重要的調查。政府必須知道各行各業目前有多少人就業、薪水是多少、上個月有多少新人加入職場、有多少人離開職場及有多少人失業等等。許多政府部門和民間企業在研擬政策的時候,這些都是很重要的參考指標。
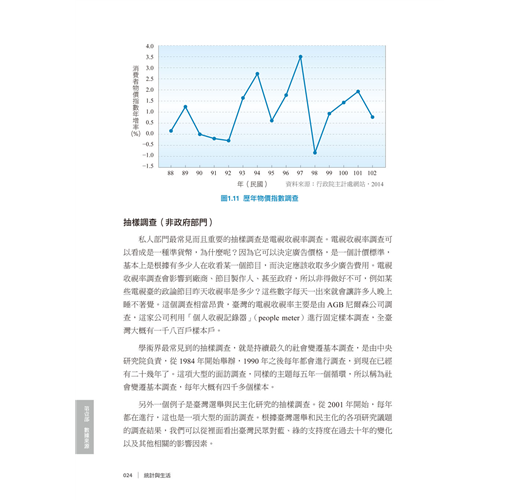
第二個調查是物價調查,參考圖1.11。政府每十天調查一次全臺灣的物價, 調查單位會先定義很多標準,譬如設定424種商品,每旬調查,同一個物品在臺北、臺中、新竹及高雄,各賣多少錢,分別記錄下來,每個月再根據這些物價資訊編製成物價指數(請參考第7章),而這個物價指數是可以拿來做很多其他延伸的用途,例如許多人能藉以知道現在的薪水比起物價來講是相對上升還是下降。
第三個調查是家庭收支調查,這個調查結果常常可以在報章雜誌上看到。家庭收支調查全臺灣13,776個樣本戶,一年調查一次,可以經由調查結果推估臺灣平均每戶家庭所得是多少、每戶所得消費支出是多少和每戶可支配所得是多少等等。
抽樣調查(非政府部門)
私人部門最常見而且重要的抽樣調查是電視收視率調查。電視收視率調查可以看成是一種準貨幣,為什麼呢?因為它可以決定廣告價格,是一個計價標準, 基本上是根據有多少人在收看某一個節目,而決定應該收取多少廣告費用。電視收視率調查會影響到廠商、節目製作人、甚至政府,所以非得做好不可,例如某些電視臺的政論節目昨天收視率是多少?這些數字每天一出來就會讓許多人晚上睡不著覺。這個調查相當昂貴,臺灣的電視收視率主要是由AGB 尼爾森公司調查,這家公司利用「個人收視記錄器」(people meter)進行固定樣本調查,全臺灣大概有一千八百戶樣本戶。
學術界最常見到的抽樣調查,就是持續最久的社會變遷基本調查,是由中央研究院負責,從1984年開始舉辦,1990年之後每年都會進行調查,到現在已經有二十幾年了。這項大型的面訪調查,同樣的主題每五年一個循環,所以稱為社會變遷基本調查,每年大概有四千多個樣本。
另外一個例子是臺灣選舉與民主化研究的抽樣調查。從2001年開始,每年都在進行,這也是一項大型的面訪調查。根據臺灣選舉和民主化的各項研究議題的調查結果,我們可以從裡面看出臺灣民眾對藍、綠的支持度在過去十年的變化以及其他相關的影響因素。
此外,我們也經常從媒體見到各種滿意度調查,例如總統的施政滿意度調查,或是各縣市長的施政滿意度調查,這些數據經常使得政治人物十分緊張。
由於普查是研究全部母體,需要龐大的經費與眾多的工作人員,也比較耗費時間。與抽樣調查相較之下,普查既費時又花錢,以時間和金錢的角度而言,抽樣調查當然比普查來得划算。
1.4 實驗性資料――操之在我
實驗法是蒐集資料的另外一個方式。我們做實驗總是有目的性,利用實驗法所得到的資料稱為實驗性資料,參考圖1.12。農人想要糧食增產, 所以就對農作物施灑肥料,到底施肥可以增加多少糧食產量呢?又例如減肥藥能不能降低體重?最近我們在打流行性感冒疫苗,是不是會引起副作用?有什麼證據?這些都需要做實驗,然後根據實驗的結果作推論。
假設我們要做一個有關減肥藥的實驗,蒐集身體質量指數(body mass index, BMI)超過27的人,隨機把他們分成兩組,一組服用減肥藥,另一組服用安慰劑。所謂安慰劑(placebo)就是裡面沒有減肥藥的成分,但是讓參加實驗的人也有服藥的行為和感覺。所有參加此實驗的人在做實驗之前先測量一次體重,然後持續服用藥物(或安慰劑)一段時間後,再測量一次體重,看兩組的體重變化是不是有差別,藉此證實減肥藥的效果。
其實一般人的生活每天可能都在當白老鼠或是參與實驗。一個簡單的例子就是7-ELEVEN便利商店,其據點有好幾千家,想一想如果廠商願意將一個新的產品推出去上市,上市之前要先決定一些策略。例如要怎麼樣包裝?用橢圓型包裝、圓形包裝、罐裝包裝還是其他包裝;要弄成什麼顏色?粉紅色、紅色、黑色、白色還是銀色;定價要訂在哪裡?10元、20元、21元還是29元等等。假設有三個因素要決定,每一種因素有好幾個分類方法,像包裝分成四種形狀,顏色分成五種顏色,測試的價格可能分成五種價格,所有因素的分類就有很多種組合,每一種組合至少要有兩家便利商店來做實驗,消費者買了東西以後,電腦就會自動記錄,總部就會知道哪一種商品賣掉多少個。等實驗結束,廠商根據所有蒐集到的資料,發現銀白色包裝,罐裝一瓶,價格29元,是銷量最好的組合, 而這個組合就是新產品的最佳組合,這就是實驗性資料的威力!
1.5 數據的展示――數字會說話
在生活上我們經常可以看到一些數字,例如楊同學昨天考試考了58分,參考圖1.13,這什麼意思?一點意義都沒有!為什麼?因為沒有其他資訊,58分搞不好是全班最高分啊, 所以只給58分一個數據沒有任何意義。我們也許要先看一下其他相關的一些數據,例如全班平均幾分,最高、最低是多少,中位數是多少,然後再去看考了58分有什麼意義。
第二個例子是林同學就讀臺灣大學,每個月房租不算,花費6,500元,參考圖1.14。同理,如果沒有一些相對數據的話,我們不知道每個月花6,500 元到底是多還是少?如果我們調查臺大學生的花費,每月花費的中位數是5,500元,這表示臺大學生有一半的人每個月花5,500元以上,一半的學生每個月花費不到5,500元。若有中位數可供參考,則林同學每個月花費6,500元, 比一半的同學還多,至少表示他沒有省錢。
第三個例子是王太太剛生下一名女嬰重量是3,485公克,參考圖1.15。一般人看到這筆數據應該是毫無概念,但如果給一個參考數據,例如臺灣出生的女嬰體重的中位數是3,000公克,換句話說,我們知道一半的女嬰重量在3,000公克以上,一半的女嬰重量在3,000公克以下,所以生了一個3,485公克的女嬰應該算是很重的,這樣女嬰的體重意義就比較清楚了。以上這些例子說明我們必須要有一些參考數據再來研判,解讀數字才有意義,否則的話,單單一筆數據是毫無用處的。
兩個變數之間的關係
我們看到一些資料時,通常會想知道變數跟變數之間的關係,可是什麼叫做這個變數跟那個變數有關呢?前面我們提到觀察性資料變數之間只能推論相關程度, 只有實驗性資料才可以推論因果關係。也就是說,如果只是觀察到很多現象的話, 只能說什麼跟什麼有很高的相關,不能下結論說什麼導致什麼,因為因果關係的標準比較嚴格,需要有科學上的證明或是依據。
讓我們看看以下的幾個例子,第一個例子是某國總統候選人A獲勝和各地區廢票率的關係,參考圖1.16。一位研究員在研究某國的選舉資料後發現,候選人A得票率很高的地方,廢票率也非常高。看到這個現象可以下結論說廢票率揚升跟候選人A的得勝有關係嗎?甚至說廢票率揚升導致候選人A得勝嗎?這是兩個完全不一樣的科學邏輯。實際上如果仔細去做分析的話,候選人A得票率很高的地區,廢票率確實也很高,但是那個地區選民的年紀相對來講也是很高,也就是六十歲以上的人口比例很高; 其次那個地區選民不認識字的比例相對來講也比較高,所以有很多變數之間的關係都有非常高的相關,但是這筆資料無法證明,廢票率揚升導致候選人A得勝,如果想要得到這樣的結論,必須還要有更堅強的科學證據支持。
第二個例子是某校學生大學入學考試,英文成績跟數學成績的關係,參考圖1.17。大考中心有各式各樣的數據可以做研究,我們可以分析每個學校學生入學考試的成績,不同學校學生英文成績跟數學成績的相關可能都不一樣。像某所大學的學生,英文成績跟數學成績可能有很高程度的相關,但是另一所大學的學生,英文成績跟數學成績卻可能沒有什麼關係。
另外一個典型的例子是抽菸跟癌症的關係,參考圖1.18。很多醫學研究認為,抽菸跟癌症是有因果關係,但是一般來講,通常拿到抽菸和癌症的資料都是觀察性資料, 所以在科學上只能說,抽菸跟癌症有非常高的相關,但是要推論到抽菸導致癌症,後面需要有更堅強的科學驗證。那要怎麼樣做這個實驗呢?像是拿老鼠來做實驗,把老鼠分兩組,一組抽菸,另一組不抽菸,除了是否抽菸的因素外,兩組老鼠的身體條件,生長環境及飲食等都完全一樣,避免其他可能影響罹患癌症的因子,然後根據實驗結果,才能證實會抽菸是否可能導致癌症。
事實上,學術界對於這個議題已經有一些共識,即如果想推論兩個變數之間有因果關係的話,必須滿足三個要件:第一個要件是原因變數X在前,後果變數Y在後,換句話說,先發生原因變數,再出現後果變數,這樣才可以建立一個因果關係的先決條件;例如,如果要驗證「龍生龍,鳳生鳳」這句話,也就是父母親的社會經濟地位造就了兒女的社會經濟地位,一定先有父母親的社會經濟地位,才可能會有兒女的社會經濟地位,所以一定是一個在前一個在後,這是建立因果關係的第一個要件。第二個要件是兩個變數之間要有非常高的相關程度,這一點是當然要件。第三個要件是最難的地方,必須是這個後果變數只有跟這個原因變數有非常高的相關,但是跟其他變數沒有相關,換句話說,只有這個原因變數X對後果變數Y有非常高的相關。像剛剛提到過的廢票率上揚,它是一個變數X,某國總統候選人A當選在後,也可能有非常高的相關,但是與廢票率上揚有高相關的變數非常多,說不定投票當天氣溫驟降導致民眾出門投票意願下降,所以廢票率上揚並不是唯一的原因變數,必須這三個要件都成立,才有可能推展到因果關係。
第一章 資料從哪裡來
1.1 導讀
學習統計學的第一步,就是要認識「資料」(data),了解資料的基本型態及如何蒐集資料。而當我們在蒐集資料過程中,必須符合道德規範,以及使用正確地衡量工具,才能進行下一個步驟抽樣資料(第2 章)。本章節將介紹資料的不同型態、觀察性資料、實驗性資料、數據的展示、蒐集資料的道德規範及資料衡量工具的信度與效度。
1.2 資料的型態
我們要處理資料,首先必須知道資料「長」什麼樣子,表1.1就是一個例子。從裡面我們可以得到很多訊息,例如某病人的年齡幾歲?身高多高?體重多少?教育程度如何?性...
作者序
增訂版序言
劉仁沛、洪永泰、蕭朱杏、陳宏
統計觀念與統計數字的意義不但在各行業間及各學門上是不可缺少的工具,更是一般國民所必備的素養之一。鑒於統計之重要性,國立臺灣大學前教務長兼統計教學中心主任,現任行政院衛生福利部部長蔣丙煌教授於2007年委託臺灣大學「統計教學中心」開授「A6:量化分析與數學素養」領域的「統計與生活」通識課程。「統計與生活」開授初期採用美國出版公司所發行的統計教材為教科書,使用後發現所使用的例子、數據與習題均為國外的經驗,而與國內學生生長環境與日常生活的實例與問題並無任何交集,導致教學品質及學生學習效益無法達到預期成果。所以當時任課教師劉仁沛教授、洪永泰教授、蕭朱杏教授、陳宏教授決定以臺灣與華人地區的實際例證與數據為基礎、使用正體中文編著華人第一本統計通識課程的教科書,達到學生輕鬆有效率學習統計的目標。在蔣丙煌前教務長大力支持及鼓勵下,「統計與生活」第一版於2010年3月順利出版。
本書出版後廣受好評,並有許多國內大學亦採用本書為其統計通識課程教科書,而臺大「統計與生活」自2007年第一學期開授以來已有2,559位同學修習本課程,另外有33位曾任本課程討論課助教。同學及助教均對本書提出不少建議,再加上本書出版亦滿五年。在這五年中,統計有許多新的發展,如大數據(Big Data),食物安全及伊波拉病毒等問題的出現。另外,教學方法在這五年中亦發生革命性的改變,如翻轉教室及深碗學習。為了因應這些變化及增進本課程的教學深度及廣度,除了將「統計與生活」課程納入臺灣大學開放性課程(NTU Open Course Ware)外,亦將改編《統計與生活》教科書,出版增訂的第二版。
《統計與生活》第二版保留第一版的風格,不使用枯燥無味且艱深的統計數學用語,而以口語與人性化的方式撰寫臺灣的數據與國人切身的統計議題,生動地解釋正確的統計觀念,並用清晰及易懂的圖表呈現日常生活與國人息息相關的統計議題,所以本書不但是一本可作為統計通識課程的教科書,更是一本絕佳適合一般大眾的統計科普書籍。
本書第二版的架構亦與第一版相同,分為數據來源、數據整理、機率觀念與統計推論四大部分,在內容部分除了更正第一版小部分文字上的錯誤外,亦加入大數據與社群及網路資料的介紹,數據蒐集、分析及解讀上的倫理問題與國人兒童男女生長曲線的介紹等新的內容。另外,也更新許多實例及數據。因為本書主要任務為統計通識課程的教科書,所改第二版也增加及擴編習題及討論議題以達到深碗學習的目的。
本書的架構設計是配合國內目前每學期16週上課週數規劃(期中考週、期末考週除外)。每一部分可供四週上課的教材。我們亦建議採用本書上課時,可不用講授理論、定理與公式的推導,盡量使用本書的例子與數據介紹統計正確的觀念及使用統計數字說故事。課程安排為三學分,包括兩小時的課堂講演與一小時小組討論。因為「統計與生活」通識課程採用200人大班教學,20人小組討論的教學模式,所以小組教學助理擔任非常重要的任務。每一週的討論課程均要選擇與上課內容有關的討論議題探討生活相關的統計問題,並可將學生分成3~5人小組,對討論議題的想法寫成期中/期末報告並做成海報,成績由同學互評及教師評分,並選出最優秀的5~10組上臺報告。如此可藉由同儕間腦力激盪,互相討論觀摩與學習及課程教師與教學助理指導下能充分認識統計在日常生活的重要性及相關性。
「統計與生活」通識課程的開設及《統計與生活》教科書第二版的出版首先要感謝臺大前教務長蔣丙煌教授及現任教務長莊榮輝教授的支持與指導。同時也要感謝「統計教學中心」成員劉畢琳小姐協助本書第二版的編修及校對等各項事務,更感謝曾經修習「統計與生活」通識課程的同學們及擔任課程的教學助理所提供的寶貴建議與實例。我們亦要特別感謝下列教學助理提供第二版新的習題與討論議題:流行病學與預防醫學研究所王彥雯、宋豐伃、高瑋怡、陳建瑋、黃紫渲、賴穎婕,農藝所林昭京、陳建郎、劉素萍及蕭雅純共十位助教(按筆畫順序排列)。
增訂版序言
劉仁沛、洪永泰、蕭朱杏、陳宏
統計觀念與統計數字的意義不但在各行業間及各學門上是不可缺少的工具,更是一般國民所必備的素養之一。鑒於統計之重要性,國立臺灣大學前教務長兼統計教學中心主任,現任行政院衛生福利部部長蔣丙煌教授於2007年委託臺灣大學「統計教學中心」開授「A6:量化分析與數學素養」領域的「統計與生活」通識課程。「統計與生活」開授初期採用美國出版公司所發行的統計教材為教科書,使用後發現所使用的例子、數據與習題均為國外的經驗,而與國內學生生長環境與日常生活的實例與問題並無任何交集,導致...
目錄
增訂版序言
推薦序
序言
第壹部 數據來源
第1章 資料哪裡來
第2章 抽樣資料
第3章 實驗設計資料
第貳部 數據整理
第4章 資料之圖表展示
第5章 資料之敘述
第6章 兩個變數之關係
第7章 物價指數和政府統計
第參部 機率觀念
第8章 機率
第9章 機率模型
第10章 模擬
第11章 期望值
第肆部 統計推論
第12章 信賴區間
第13章 顯著性檢定
第14章 統計推論的應用
第15章 交叉列表與卡方檢定
附錄
參考文獻
索引
增訂版序言
推薦序
序言
第壹部 數據來源
第1章 資料哪裡來
第2章 抽樣資料
第3章 實驗設計資料
第貳部 數據整理
第4章 資料之圖表展示
第5章 資料之敘述
第6章 兩個變數之關係
第7章 物價指數和政府統計
第參部 機率觀念
第8章 機率
第9章 機率模型
第10章 模擬
第11章 期望值
第肆部 統計推論
第12章 信賴區間
第13章 顯著性檢定
第14章 統計推論的應用
第15章 交叉列表與卡方檢定
附錄
參考文獻
索引
商品資料
出版社:國立臺灣大學出版中心出版日期:2015-08-03ISBN/ISSN:9789863500865 語言:繁體中文For input string: ""
裝訂方式:平裝頁數:384頁
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。


 2收藏
2收藏

 5二手徵求有驚喜
5二手徵求有驚喜