人工智慧的發展就是要讓電腦具備獨立思考的能力,而強化式學習(Reinforcement Learning)就是訓練 AI 如何決策的一套方法,是最具產業發展潛力的熱門技術,可以有效解決生活中許多難以突破的問題,包括產業自動化、自動駕駛、電玩競技遊戲以及機器人等。
Deepmind 將強化式學習應用於開發圍棋 AI 上,打造出 AlphaGo,並連續擊敗李世乭、柯潔等世界第一流的圍棋高手,這段情節想必你並不陌生。而接續發展出來的 AlphaZero 不僅實力更強大,而且不侷限於單一棋類,可以從零開始訓練、不需要人類棋譜,被視為是 AGI 通用式人工智慧,震撼了整個 AI 產業界。
以強化式學習為主幹的 AlphaZero 雖然備受矚目,但對於多數讀者而言,要讀懂 AlphaZero 的論文並不容易,而且論文中並未公開程式碼,紙上談兵就要了解相關細節實在難如登天,本書將透過實作帶您揭開 AlphaZero 神秘的面紗。不用棋譜 (訓練資料) 怎麼進行訓練?強化式學習在 AlphaZero 扮演甚麼角色?為甚麼一套演算法可以適用不同規則的棋類或遊戲?論文沒有講清楚的都在這裡!
在這本書中,你將學到:
● 從深度學習開始,打下紮實基礎,包括 Artificial Neural Network、CNN、ResNet。
● 各類強化式學習演算法的精髓,包括:ϵ-Greedy、UCB1、Policy Gradient、Q-Learning、SARSA、Deep Q-Network (DQN)。
● 理解人工智慧中做出最優決策的方法 - 賽局樹演算法,包括 Minimax Algorithm、Alpha-beta Pruning、Monte Carlo method、Monte Carlo tree search。
● 用 Python 實作 AGI 通用演算法 - AlphaZero,只需修改規則就能稱霸井字遊戲、四子棋、黑白棋、動物棋等不同遊戲。
本書特色:
強化式學習有多強,用 Python 實作見真章!
AlphaZero 結合了深度學習、強化式學習和賽局樹演算法,背後涉及了許多相關技術,網路上雖然可以找到不少討論或教學文章,但內容多半只是原始論文的隻字片段,實作細節也交代不清楚,對於有心了解 AlphaZero 核心技術的讀者來說幫助很有限,往往只是越看越模糊,也不知道誰說得對。
本書以大量圖說、實例詳細說明 AlphaZero 各種相關的演算法,在實作的過程中,你可以親自與 AI 互動,實際體驗 AI 從零開始逐漸累積實力的過程,確實了解強化式學習跳脫人類思維所做的每一步決策,釐清演算法的每一個細節。全書內容經過施威銘研究室監修,只要遇到比較複雜的演算法或程式邏輯,小編都會額外補充,講不清楚就加上圖解,再不清楚就手算一遍,一頁一頁秀給你看,保證一定讓你看得懂、做得到。
● 以大量圖說、實例 、示意圖帶你高效學習書中的演算法 ,程式碼都有詳細的註解說明
● 深度學習、強化式學習、賽局樹等各種相關演算法逐一解析、詳細說明
● 活用 Google 免費的 Colab 雲端開發環境,並提供線上更新操作手冊 ,包括連線時間限制的處理以及 GPU/TPU 的使用說明
● 從 AlphaGo、AlphaGo Zero 到 AlphaZero,原始演算法和模型架構剖析
● 一步一步解說如何將遊戲規則轉換為程式邏輯,學習賽局資料的預處理程序
● 提供預訓練好的現成模型,立即套用、馬上對戰 ,幫你節省動輒 20 小時以上的訓練時間
作者簡介:
布留川 英一(Furukawa Hidekazu)
1975年生於日本群馬縣,會津大學電腦理工學院電腦軟體學系畢業。自2000年起,於 DWANGO Co., Ltd. 從事行動應用程式之研發工作。2005年後,於 UEI Corporation 開發智慧型手機與雙足機器人之應用程式,2013年參與了強調手寫觸感的平板電腦「enchantMOON」的開發。2017年起,則於 GHELIA 從事人工智慧、VR 與 AR 之研發工作。
目錄
[簡要目錄]
前言
本書架構
第1章 AlphaZero 與機器學習概要
1-0 AlphaGo、AlphaGo Zero 與 AlphaZero
1-1 深度學習基礎
1-2 強化式學習基
1-3 賽局樹演算法基礎
第2章 準備 Python 開發環境
2-0 Google Colab 之概要
2-1 Google Colab 的使用方法
2-2 建構本地端的 Python 開發環境
第3章 深度學習
3-0 利用神經網路進行手寫數字辨識
3-1 利用神經網路預測住宅價格
3-2 利用卷積神經網路(CNN)進行影像辨識
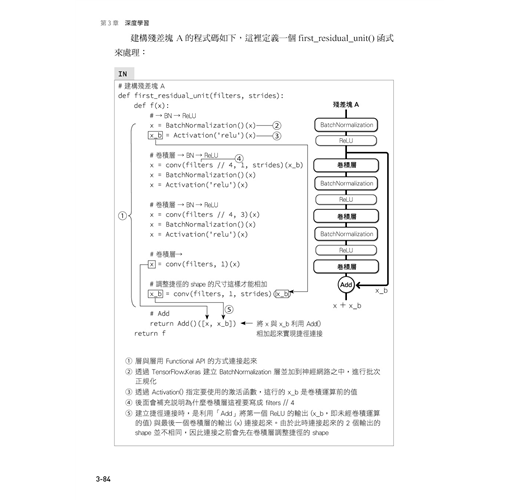
3-3 利用殘差網路 (ResNet) 進行影像辨識
第4章 強化式學習
4-0 多臂拉霸機範例
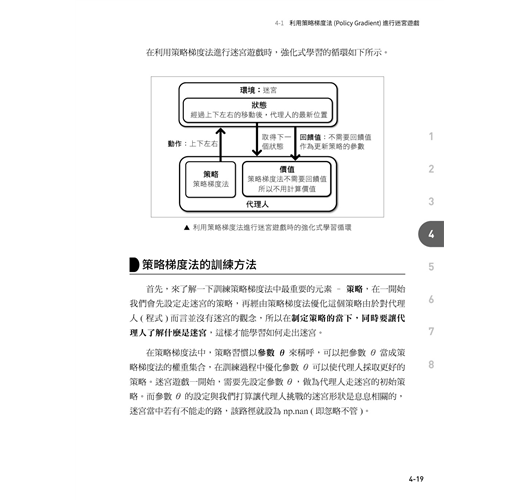
4-1 利用策略梯度法 (Policy Gradient) 進行迷宮遊戲
4-2 利用 Sarsa 與 Q - Learning 進行迷宮遊戲
4-3 利用 Deep Q-Network 遊玩木棒平衡台車
第5章 賽局樹演算法
5-0 利用 Minimax 演算法進行井字遊戲
5-1 利用 Alpha-beta 剪枝進行井字遊戲
5-2 利用蒙地卡羅法進行井字遊戲
5-3 利用蒙地卡羅樹搜尋法進行井字遊戲
第6章 AlphaZero 的機制
6-0 利用 Tic-tac-toe 進行井字遊戲
6-1 對偶網路
6-2 策略價值蒙地卡羅樹搜尋法
6-3 自我對弈模組
6-4 訓練模組
6-5 評估模組
6-6 評估最佳玩家
6-7 執行訓練循環
第7章 人類與 AI 的對戰
7-0 建立執行 UI 的本機端開發環境
7-1 利用 Tkinter 建立 GUI
7-2 人類與 AI 的對戰
第8章 將 AlphaZero 演算法套用到不同遊戲上
8-0 四子棋
8-1 黑白棋
8-2 動物棋
[簡要目錄]
前言
本書架構
第1章 AlphaZero 與機器學習概要
1-0 AlphaGo、AlphaGo Zero 與 AlphaZero
1-1 深度學習基礎
1-2 強化式學習基
1-3 賽局樹演算法基礎
第2章 準備 Python 開發環境
2-0 Google Colab 之概要
2-1 Google Colab 的使用方法
2-2 建構本地端的 Python 開發環境
第3章 深度學習
3-0 利用神經網路進行手寫數字辨識
3-1 利用神經網路預測住宅價格
3-2 利用卷積神經網路(CNN)進行影像辨識
3-3 利用殘差網路 (ResNet) 進行影像辨識
第4章 強化式學習
4-0 多臂拉霸機範例
4-1 利用策略梯度法 (Poli...
購物須知
退換貨說明:
會員均享有10天的商品猶豫期(含例假日)。若您欲辦理退換貨,請於取得該商品10日內寄回。
辦理退換貨時,請保持商品全新狀態與完整包裝(商品本身、贈品、贈票、附件、內外包裝、保證書、隨貨文件等)一併寄回。若退回商品無法回復原狀者,可能影響退換貨權利之行使或須負擔部分費用。
訂購本商品前請務必詳閱退換貨原則。